
 机器学习概念
机器学习概念
机器学习是从一系列观察中提取某种知识和模式,有三个主要分支:监督学习(也被称为“标记数据”)、无监督学习、强化学习(给出好到什么程度和坏到什么情形的评价)。其中,监督学习算法是已经预先设定存在的,可以针对回答不同类型的问题选择不同的算法,实际上非常适合解决预测答案的问题,监督学习的常用算法包括K-邻近算法、线性回归、局部加权线性回归、朴素贝叶斯算法、支持向量机、Ridge回归、决策树、Lasso最小回归系数估计等;无监督学习适合于解决分类的问题,分类的结果可以通过一些方式来检验,如果结果不理想,可以通过迭代进行聚类和测试,无监督学习的常用算法包括K-均值、最大期望值算法、DBSCAN、Parzen窗设计等。
机器学习呈现迅猛发展,主要有三个原因:
第一个原因是数据,因为机器学习需要大量的数据,而在当今获得数据的能力越来越强,越来越方便。
第二是计算能力的提高,GPU非常擅于做矩阵运算,机器学习需要的就是矩阵运算,所以GPU就可以把它运用到机器学习的领域。
第三个原因就是算法,在国际上有大量算法的大赛,百度、科大讯飞企业在算法大赛上都取得很好的成绩,机器学习日益火爆。
 决策树算法
决策树算法
决策树算法
决策树算法是是目前人工智能应用最为广泛的归纳推理算法之一,其典型算法有ID3,C4.5,CART等。国际权威的学术组织,数据挖掘国际会议ICDM (the IEEE International Conference on Data Mining)在2006年12月评选出了数据挖掘领域的十大经典算法中,C4.5算法排名第一。C4.5算法是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法。C4.5算法产生的分类规则易于理解,准确率较高。
决策树算法的优点如下:
(1)分类精度高;
(2)生成的模式简单;
(3)对噪声数据有很好的健壮性。
第一步,决策树的生成:由训练样本集生成决策树的过程。一般情况下,训练样本数据集是根据实际需要有历史的、有一定综合程度的,用于数据分析处理的数据集。
分析内容(要分析和决策的问题)穷尽 问题的各种状态(情景)穷尽 决定问题的因素穷尽 导致问题产生的原因穷尽 对回答问题的回答结论穷尽
第二步,决策树的剪枝是对上一阶段生成的决策树进行检验、校正和修下的过程,主要是用新的样本数据集(称为测试数据集)中的数据校验决策树生成过程中产生的初步规则,将那些影响预衡准确性的分枝剪除。在实际构造决策树时,通常要进行剪枝,这时为了处理由于数据中的噪声和离群点导致的过分拟合问题。剪枝有两种:
?先剪枝——在构造过程中,当某个节点满足剪枝条件,则直接停止此分支的构造。
?后剪枝——先构造完成完整的决策树,再通过某些条件遍历树进行剪枝。
神经网络
神经网络(Neural Network)又称平行分布式处理(Parallel Distributed Processing ),在数据分析领域,是一种灵活性较强的非线性模型,被广泛应用于问题的预测方面。人工神经网络简称神经网络,是一种模仿生物神经网络的结构和功能的数学计算模型,它的构筑理念是受到生物(人或其他动物)神经网络功能的运作启发而产生的。它能从已知数据中自动的归纳规则,获得这些数据的内在规律,具有很强的非线性映射能力。人工神经网络己经广泛的应用于模式识别、信号处理及人工智能等各个领域。
BP(Back Propagation)网络是1986年提出,是目前应用最广泛的神经网络模型之一。
BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
BP神经网络模型拓扑结构(见下图)包括输入层(input)、
隐含层(hide layer)和输出层(output layer):输入层(Input layer),众多神经元(Neuron)接受大量输入信息。
输出层(Output layer),信息在神经元链接中传输、分析、权衡,形成输出结果。隐藏层(Hidden layer),简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。
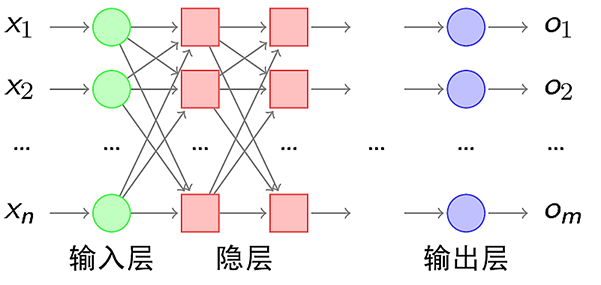 图1 BP神经网络模型拓扑结构
图1 BP神经网络模型拓扑结构
BP神经网络是一种单向传播的多层前馈型神经网络,是前馈网络的核心部分。它的整个学习过程采用BP算法,
即“误差反向传播算法”,随着这种误差反向传播的不断进行,网络向输入模型响应的正确率不断提高的方向转变。
用来解决风险预警或预测问题的BP神经网络可以被视为一个对线性组合后的变量进行非线性变换,然后再循环线性组合、非线性变换的统计方法。首先,给网络上各节点的连接权值赋予随机值,将输入层所对应的模式输入给网络,网络将输入模式加权求和并与阈值比较,再进行非线性运算,得到网络的输出。如果输出结果正确,则将连接权值增大,以便使网络再次遇到同样模式输入时,仍然能做出正确的判断。如果输出结果错误,则把网络连接 权值朝着减小综合输入加权值的方向调整,其目的在于使网络下次再遇到同样模式输入时,减小犯同样错误的可能性。 如此操作调整,当给网络多次输入若干个输入模式,网络按以上学习方法进行多次学习后,网络判断的正确率将大大提高。这说明网络对模式的学习已经获得了成功,它已将这两个模式分布地记忆在网络各个节点的连接权值上。当网络再次遇到其中任何一个模式时,能够做出迅速、准确的判断和识别。
要构建BP网络需要确定网络层数、每层节点数、传递函数、学习算法等。
确定这些选项时有一定的指导原则,但更多的是靠经验和试凑。
 深度学习
深度学习
深度学习是机器学习领域一个全新的研究方向,其目的是建立多层神经网络,以期能够模仿人脑的机制来分析和解释图像,音频和文本等数据。深度学习的本质是利用海量的训练数据( 可为无标签数据),通过构建多隐层的模型,去学习更加有用的特征数据, 从而提高数据分类效果,提升预测结果的准确性。
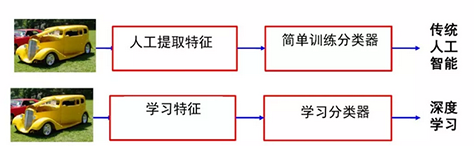
深度学习与传统人工智能相比,最大的特点在于能够自动学习与任务相适应的特征。
深度学习通过进一步发现和研究中间变量扩展和延伸机器学习,三方面的因素导致深度学习到达新兴技术曲线的顶端位置:一是前所未有的大量数据的可获取,包括以前难以处理的数据;二是算法的改进、模型的优化,能够处理快速增长的数据集;三是深层学习硬件平台的升级换代(拥有数以万计的集群芯片和基于GPU的硬件架构的超级计算机)。
深度学习主要应用包括图像和语音识别中的卷积神经网络;
自然语言处理和翻译中的递归神经网络;生物信息学中的自动编码的人工神经网络。
建议在能力范围内把深度学习的数据作为长期投资的重点,因为正确数据的价值会随着时间增长。
对于产业来说,深度学习对所有行业都具有转换和颠覆潜力。
 深度多层神经网络
深度多层神经网络
深度学习是以不少于2个隐含层的神经网络对输入进行非线性变换或表示学习的技术,其本质上是包含多个隐含层的人工神经网络。 卷积神经网络是一种深度学习网络,包括卷积层和池化层,其先进行卷积过程再进行池化过程。 其中卷积过程的输出项作为池化层的输入项,然后将池化层结果作为下次卷积层的输入项依次类推。 卷积神经网络的关键部分如下图。
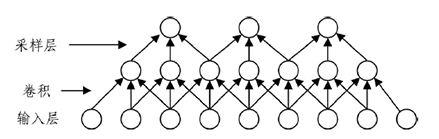 图 卷积神经网络的关键部分
图 卷积神经网络的关键部分
卷积神经网络是典型的前馈神经网络,由多个单层卷积神经网络组成的可训练的多层网络结构。 每个单层卷积神经网络包括卷积、非线性变换和下采样3 个阶段,如下图。
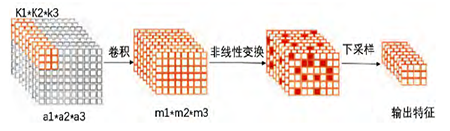 图 卷积神经网络的3个阶段
图 卷积神经网络的3个阶段
在训练卷积神经网络时, 最常用的方法是采用反向传播法则以及有监督的训练方式,算法过程如下图。
 图 卷积神经网络训练过程
图 卷积神经网络训练过程
 机器学习在财务中的应用
机器学习在财务中的应用
 基于机器学习的智能共享作业
机器学习模式下,计算机可以通过经大量带有人工判断结果的 "标签"任务的训练来优化现有的规则,通过机器学习补充更多靠人难以解读出来的规则,同时也可以结合大量的外部数据进行辅助学习,如对市场上经常开具假发票的案例的学习,补充原本人的逻辑难以补充的假发票黑名单供应商规则。通过机器学习,现有的规则作业能够真正意义上转变为智能作业,并实现对产能的进一步释放和提升。
基于机器学习的智能共享作业
机器学习模式下,计算机可以通过经大量带有人工判断结果的 "标签"任务的训练来优化现有的规则,通过机器学习补充更多靠人难以解读出来的规则,同时也可以结合大量的外部数据进行辅助学习,如对市场上经常开具假发票的案例的学习,补充原本人的逻辑难以补充的假发票黑名单供应商规则。通过机器学习,现有的规则作业能够真正意义上转变为智能作业,并实现对产能的进一步释放和提升。
 基于机器学习的智能报告与会计
机机器学习确实能够去完整现有的规则库,但会计作业和审核作业还有所不同,其本身就是建立在高度标准化的规
则基础上的, 我们可能要评估一下,是否进一步的依靠人的经验来拆借规则,并深化规则应用比使用机器学习的模
式会更有效率。 智能报告方面中的固化结构可以用规则来形成,但讲故事的部分,可以使用机器学习的方式,通过
训练大量“报告特征-好市场反应”的训练题来让机器学会编写怎样的报告更能够满足投资人口味。
基于机器学习的智能报告与会计
机机器学习确实能够去完整现有的规则库,但会计作业和审核作业还有所不同,其本身就是建立在高度标准化的规
则基础上的, 我们可能要评估一下,是否进一步的依靠人的经验来拆借规则,并深化规则应用比使用机器学习的模
式会更有效率。 智能报告方面中的固化结构可以用规则来形成,但讲故事的部分,可以使用机器学习的方式,通过
训练大量“报告特征-好市场反应”的训练题来让机器学会编写怎样的报告更能够满足投资人口味。
 基于机器学习的智能风险控制
通过机器学习,计算机能够不断的完善算法,从而对所有进入财务流程的单据进行风险分级,
并针对不同的风险等级设置相匹配的业务流程。同时,基于监督学习、无监督学习的各种算法,
去发现风险线索。在智能风控模式下,我们希望计算机能够更加精准的帮助我们去命中疑似风险案件,
并非绝对拦截,是我对这一应用场景有别于智能共享作业审核的定义。
基于机器学习的智能风险控制
通过机器学习,计算机能够不断的完善算法,从而对所有进入财务流程的单据进行风险分级,
并针对不同的风险等级设置相匹配的业务流程。同时,基于监督学习、无监督学习的各种算法,
去发现风险线索。在智能风控模式下,我们希望计算机能够更加精准的帮助我们去命中疑似风险案件,
并非绝对拦截,是我对这一应用场景有别于智能共享作业审核的定义。
 基于机器学习的智能财务管理
在非运营的财务业务中,同样可以找到非常多的可能应用场景。如基于机器学习的经营分析,基于机器学习的资源配置等等。建立的机器学习系统,销售团队可以设定定制化的分类——这里没有预先设置好的分类。这种做法让销售团队能够在销售过程中进行定义和修改,依据特别的情况来更新设定以满足相应的需求。机器学习平台足够灵活,因此可以快速地适应销售策略和目标的变化。
基于机器学习的智能财务管理
在非运营的财务业务中,同样可以找到非常多的可能应用场景。如基于机器学习的经营分析,基于机器学习的资源配置等等。建立的机器学习系统,销售团队可以设定定制化的分类——这里没有预先设置好的分类。这种做法让销售团队能够在销售过程中进行定义和修改,依据特别的情况来更新设定以满足相应的需求。机器学习平台足够灵活,因此可以快速地适应销售策略和目标的变化。

